
Il termine Intelligenza Artificiale (I.A. o nell’anglosassone AI) viene introdotto ufficialmente nel linguaggio informatico nel 1956, in occasione del congresso del Darmouth College di Hannover, al quale partecipano i più importanti rappresentanti della nuova disciplina e designa una branca della scienza informatica ed ingegneristica che si occupa dell’individuazione di modelli per lo sviluppo di algoritmi che consentano alle macchine, o calcolatori, di emulare abilità intelligenti almeno in domini specifici. E’ un ramo dell’informatica che permette la programmazione e progettazione di sistemi sia hardware sia software in grado di dotare le macchine di determinate caratteristiche che vengono considerate tipicamente umane quali, ad esempio, le percezioni visive, spazio-temporali e decisionali. Si tratta cioè, non solo di intelligenza intesa come capacità di calcolo o di conoscenza di dati astratti, ma anche e soprattutto di tutte quelle differenti forme di intelligenza che sono riconosciute dalla teoria di Gardner, e che vanno dall’intelligenza spaziale a quella sociale, da quella cinestetica a quella introspettiva. Un sistema intelligente, infatti, viene realizzato cercando di ricreare una o più di queste differenti forme di intelligenza che, anche se spesso definite come semplicemente umane, in realtà possono essere ricondotte a particolari comportamenti riproducibili da alcune macchine.
“L’I.A. è al tempo stesso una scienza e un’ingegneria” (Nilsson 1998).
È una scienza perché, nel momento in cui alcuni comportamenti intelligenti vengono emulati con determinati sistemi artificiali, l’uomo consegue l’obiettivo di formulare modelli oggettivi e rigorosi e di ottenere conferme sperimentali. Questo è un indiscutibile progresso nello studio, svolto con metodi scientifici, dell’intelligenza nell’uomo.
È un’ingegneria perché, quando si ottengono dalle macchine prestazioni che emulano determinati comportamenti, ritenuti erroneamente inaccessibili all’ambito artificiale, si fornisce un oggettivo progresso al contributo che questa disciplina offre al miglioramento della vita dell’uomo.
Inizialmente, gli obiettivi dell’I.A. consistono nella creazione, nell’arco di 10 anni, di sistemi informatici in grado di:
- Battere un campione mondiale di scacchi.
- Dimostrare importanti teoremi matematici.
- Oggettivare le principali teorie del comportamento umano.
Secondo le parole di Marvin Minsky, uno dei pionieri dell’I.A., lo scopo di questa nuova disciplina è quello di “far fare alle macchine delle cose che richiederebbero l’intelligenza se fossero fatte dagli uomini”.
I settori d’indagine
Tra i suoi settori d’indagine più rilevanti, vi sono:
- I metodi per risolvere problemi in situazione di dubbio (problem solving).
- La capacità di comprendere ed elaborare il linguaggio naturale (Natural Language Processing).
- L’apprendimento automatico (machine learning).
- La rappresentazione della conoscenza e il ragionamento automatico in maniera simile a quanto fatto dalla mente umana.
- La pianificazione (planning).
- La cooperazione tra agenti intelligenti, sia software sia hardware (robot).
La disciplina dell’I.A. è divisa in due aree di pensiero fondamentali: l’Intelligenza Artificiale forte e l’Intelligenza Artificiale debole.
Intelligenza Artificiale forte
Un computer correttamente programmato può essere veramente dotato di un’intelligenza pura, non distinguibile da quella umana.
L’idea alla base di questa teoria è il concetto che risale al filosofo empirista inglese Thomas Hobbes, che sosteneva che “ragionare non è nient’altro che calcolare”: la mente umana è dunque il prodotto di un complesso insieme di calcoli eseguiti dal cervello.
”Tuttavia, il calcolatore non è semplicemente uno strumento per lo studio della mente, ma piuttosto, quando sia programmato opportunamente, è una vera mente; è possibile affermare che i calcolatori, una volta corredati dei programmi giusti, letteralmente capiscono e posseggono altri stati cognitivi” [Searle, 1980]
L’ipotesi dell’intelligenza artificiale forte, sostenuta dai funzionalisti, asserisce che le macchine che si comportano intelligentemente stiano effettivamente pensando, e non semplicemente simulando il pensiero. L’IA forte porta, dunque, ad interrogarsi sul concetto di coscienza, in quanto comprensione e consapevolezza di sé, e ci permette di riflettere su aspetti che riguardano l’etica relativa allo sviluppo di macchine intelligenti.
Intelligenza Artificiale debole
Un computer non potrà mai essere equivalente ad una mente umana, ma potrà solo simulare alcuni processi cognitivi umani senza riuscire a riprodurli nella loro totale complessità.
Macchine che agiscono come se fossero intelligenti è l’ipotesi che sta alla base dell’intelligenza artificiale debole. Secondo questa visione filosofica il calcolatore viene considerato come uno strumento potentissimo applicato allo studio della mente, che ci permette di formulare e verificare ipotesi in una maniera più precisa e rigorosa. L’intelligenza artificiale fu fondata dallo stesso John McCarthy con l’idea che l’IA debole fosse possibile. Questo perché nella proposta del seminario al Dartmouth College asseriva che ogni aspetto dell’apprendimento e dell’intelligenza potesse essere formalizzato e quindi simulato al calcolatore.
Fanno parte di questa categoria i ”sistemi basati sulla conoscenza” o ”sistemi esperti”, chiamati successivamente ”sistemi di supporto alle decisioni”.
ESPERIMENTO DELLA STANZA CINESE
La stanza cinese è un esperimento mentale ideato da Searle nell’articolo ”Minds, Brains and Programs” pubblicato nel 1980. Esso può essere considerato un esempio il cui scopo è quello di confutare la teoria dell’intelligenza artificiale forte. Con l’ipotesi che, per verificare una qualunque teoria della mente è necessario domandarsi come funzionerebbero le cose se la nostra stessa mente funzionasse secondo i principi alla base della teoria in esame, Searle formulò il suo Gedanken-experiment.
Immaginiamo di porre un uomo, di madrelingua inglese, chiuso in una stanza assieme ad un grande foglio di carta interamente ricoperto da ideogrammi cinesi. Supponiamo che l’uomo non conosca assolutamente il cinese, né in forma scritta né parlata. Come ulteriore forma di sicurezza ipotizziamo che l’individuo in questione non sia nemmeno in grado di distinguere ideogrammi cinesi da quelli giapponesi; questi simboli appaiono ad esso come ”scarabocchi privi di significato”. Insieme al primo foglio ne viene fornito un secondo, anch’esso in cinese, e con questo un set di regole per mettere in relazione i due fogli. Le regole sono scritte in inglese, quindi totalmente comprensibili all’individuo. Esse permettono di correlare un insieme di simboli in un altro insieme di simboli, identificandoli semplicemente in base alla loro forma grafica. Infine, all’uomo viene fornito un terzo foglio contenente ideogrammi cinesi e regole, queste ultime in inglese, che permettono di collegare elementi di quest’ultimo foglio con i primi due. Queste regole hanno lo scopo di insegnare a scrivere certi ideogrammi cinesi aventi una data forma, in risposta a determinati simboli assegnati nel terzo foglio, discriminati in base alla loro struttura grafica. Ad insaputa dell’uomo ”rinchiuso” nella stanza, le persone che gli forniscono questi simboli chiamano:
- scrittura, il contenuto del primo foglio,
- storia, quello del secondo,
- domande, quello del terzo,
- programma, l’insieme delle regole consegnate all’uomo
- risposte alle domande, i simboli che l’uomo restituisce in risposta al contenuto del terzo foglio.
Per complicare le cose, Searle ipotizza che all’uomo vengano anche fornite storie in inglese, da lui comprensibili, e che successivamente risponda alle domande incentrate su tali storie, sempre in inglese. Supponiamo inoltre che l’uomo diventi particolarmente bravo ad applicare le regole, a lui fornite, per la manipolazione dei simboli cinesi e che i programmatori diventino così abili a scrivere i programmi che dall’esterno della stanza le risposte date alle domande siano indistinguibili da quelle che darebbero persone di madrelingua cinese. Nessuno potrebbe pensare che l’uomo non conosca neanche una parola di cinese perché, dall’esterno, le risposte alle domande in cinese e in inglese sono buone nella stessa misura. Nel caso del cinese però l’uomo giunge alle risposte manipolando simboli formali non interpretati, cioè si comporta come un calcolatore; esegue operazioni di calcolo su elementi specificati per via formale. L’uomo quindi può essere visto come un’istanziazione del programma del calcolatore. Dunque tornando alla questione principale, l’IA forte sostiene che il calcolatore programmato capisca le storie e che il programma, in un certo qual senso, spieghi le capacità di comprendere dell’uomo. Tuttavia, Searle ribadisce che l’uomo nella stanza, e per analogia il calcolatore, non sia in grado di comprendere una sola parola delle storie in cinese. Ciò che sta alla base del ragionamento di Searle è che la sintassi (grammatica) non è equivalente alla semantica (significato). Quindi conclude dicendo che anche eseguire un programma appropriato non è condizione sufficiente per essere una mente.
Le due declinazioni di I.A. hanno alla base la necessità di elaborare le informazioni fondamentali per i processi cerebrali attraverso dei programmi informatici.
Sono stati enunciati alcuni fondamenti teorici unanimemente considerati alla base della moderna I.A.:
- Ogni tipo di attività mentale è un calcolo.
- Il calcolo è inteso come manipolazione di simboli in base a regole prestabilite.
- Il simbolo, o rappresentazione, è un oggetto che raffigura un altro oggetto.
- Può esistere un manipolatore automatico di simboli. La nozione di calcolo intesa come manipolazione di simboli in base a delle regole descrive il funzionamento dei sistemi formali, cioè di quei sistemi che operano a partire da un insieme finito di elementi distinti e da un insieme finito di regole che descrivono le possibili trasformazioni di essi. Uno degli obiettivi dei primi studiosi di Intelligenza Artificiale consiste nella realizzazione di una macchina in grado di funzionare come un sistema formale.
Il cervello umano è una struttura molto complessa che può essere considerata come un’enorme rete neurale, i cui nodi sono costituiti da circa cento miliardi di neuroni.
Studiando la struttura biologica e fisiologica del cervello, i neuroscienziati hanno stabilito che tutte le attività intelligenti sono controllate dalla parte esterna del cervello, la corteccia cerebrale. Essa è suddivisa in diverse regioni specializzate, ognuna delle quali controlla una determinata facoltà cognitiva.
I neuroscienziati sono inoltre riusciti a ricostruire la struttura cellulare del cervello ed a capirne almeno in parte il funzionamento.
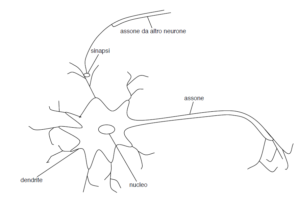
NEURONE NATURALE
NEURONE ARTIFICIALE
La struttura di ogni neurone è complessa: dal corpo cellulare (soma), partono numerose propaggini, di due tipi, che corrispondono ai due diversi canali di comunicazione tra neuroni: gli assoni ed i dendriti.
Gli assoni rassomigliano a dei fili di sezione costante. Lungo ogni assone principale si possono avere più propaggini assoniche. Sono dei canali di output, poiché trasportano all’esterno il segnale prodotto dal neurone.
I dendriti differiscono sensibilmente dagli assoni perché tendono ad assottigliarsi man mano che si allontanano dal corpo cellulare. Sono dei canali di input poiché convogliano l’informazione verso il corpo cellulare del neurone.
Il neurone è dotato di una membrana che separa l’ambiente intracellulare da quello extracellulare. In condizioni di riposo, si stabilisce una differenza di potenziale elettrico fra l’interno e l’esterno della cellula, causata dalla differente composizione chimica tra queste due regioni: all’interno della cellula, vi è una predominanza di potassio, mentre all’esterno prevale il sodio (entrambi in forma ionica).
Queste differenti concentrazioni sono dovute alle proprietà di semipermeabilità della membrana che, in assenza di perturbazioni elettriche, lascia fluire verso l’interno solo il potassio e rappresenta invece una barriera per il sodio. L’interno della membrana è a potenziale negativo rispetto all’esterno (la differenza di potenziale è di alcuni mV).
Ogni neurone può ricevere da quelli ai quali è collegato un insieme di segnali chimico-elettrici. La somma dei segnali provenienti dalle altre cellule neurali altera il valore del potenziale all’esterno del corpo cellulare; se questo supera un certo valore di soglia8, la permeabilità della membrana varia drasticamente, lasciando penetrare all’interno del corpo cellulare gli ioni di sodio.
La superficie della cellula genera un impulso di corrente che propaga l’informazione da un neurone ad un altro. Questo segnale caratteristico, detto spike, si propaga poi lungo gli assoni.
La tipica attività di un neurone consiste, quindi, nella trasmissione di una serie di impulsi elettrici. Tale serie rappresenta un segnale di una certa intensità, la cui frequenza costituisce un’ulteriore informazione.
Si può modellare il neurone come un sistema a due stati. Allo stato di riposo, ossia quando la somma dei segnali che provengono dagli altri neuroni è minore di un certo valore di soglia, il neurone non emette alcun segnale e non propaga quindi l’informazione che gli giunge. Quando invece tale somma supera la soglia, il neurone passa nello stato attivo e comincia a trasmettere l’informazione agli altri neuroni ai quali è collegato.
La connettività del sistema è determinata dalle sinapsi, ispessimenti che si formano ai punti di contatto tra ramificazione assoniche e dendritiche di due neuroni. L’interazione di due neuroni collegati da una sinapsi può essere più o meno forte, a seconda delle caratteristiche fisiche della connessione.
Si possono distinguere due tipi di connessioni: le sinapsi piuttosto sottili, o eccitatorie (dello spessore di circa 2 nm) e le sinapsi più spesse, o inibitorie (fino a 50 nm). Le prime hanno una bassa resistenza (un basso valore di soglia), che consente al segnale di propagarsi quasi intatto sino al dendrite del neurone ricevente, attivandolo. Le seconde possono invece portare ad un innalzamento della soglia e ad inibire l’attivazione del neurone ricevente.
”Can machines thinks?”[Turing, 1950]
”Possono pensare le macchine?”, `e questa la domanda che pone all’attenzione Alan Turing nel suo articolo Computing machinery and intelligence del 1950 pubblicato sulla Rivista Mind. Una domanda a cui è difficile dare una risposta, se non si è prima definito il significato dei termini macchina e pensare. È questo il motivo che portò Turing ad ideare un esperimento concettuale, un Gedanken-experiment, per stabilire se una macchina sia, o meno, in grado di pensare.
Il test di Turing è una variazione del ”gioco dell’imitazione”.
Siccome non è possibile avere accesso alla vita mentale degli altri, l’unico modo per stabilire se un soggetto sia pensante o meno, consiste nell’analizzare i suoi comportamenti.
Al gioco dell’imitazione partecipano tre persone: un uomo (A), una donna (B) ed un interrogante. L’interrogante viene chiuso in una stanza, separato dagli altri due, i quali sono a lui noti con le lettere X e Y.
- Scopo dell’interrogante: determinare quale sia l’uomo e quale la donna, ponendo domande a cui corrisponderanno risposte dattiloscritte, per evitare di fornire eccessive informazioni attraverso la voce e la calligrafia.
- Scopo di A: ingannare l’interrogante e far sì che fornisca un’identificazione errata.
- Scopo di B: aiutare l’interrogante.
Turing si chiede cosa potrebbe accadere se una macchina (C) prendesse il posto dell’uomo (A): “è vero che, modificando il calcolatore in modo da avere a disposizione una memoria adeguata, incrementando la sua velocità di azione e fornendogli una programmazione adatta, C può fare la parte di A nel gioco dell’imitazione, se la parte di B viene assunta da un essere umano?”
Per una macchina, il test di Turing consiste quindi nell’ingannare un essere umano giocando al gioco dell’imitazione, inducendolo a credere di conversare con un altro essere umano e non con una macchina.
Se, attraverso un dato numero di domande, l’interrogante non riesce a distinguere dalle risposte i due giocatori, significa che la macchina ha superato il test ed adotta quindi comportamenti intelligenti.
Il test di Turing è comportamentista, in quanto per riconoscere la macchina è necessario basarsi sulle risposte date dai due giocatori, ma anche soggettivo poiché è l’interrogante colui che deve confrontare il comportamento (in termini di risposte) dell’interlocutore con quello di un’ipotetica persona di media cultura e capacità.
La macchina ammessa al gioco è la cosiddetta “macchina universale”, in grado di simulare il comportamento di una qualsiasi macchina a stati discreti.
L’essere umano agisce a passi discreti, in termini di stati interni, segnali in ingresso e segnali in uscita: gli stati interni sono gli insiemi di proposizioni che esprimono le conoscenze possedute dall’essere umano, i segnali in ingresso sono le domande rivolte dall’interlocutore e i segnali in uscita sono le eventuali risposte date dall’essere umano in base alle sue conoscenze.
La macchina universale è però un’idealizzazione, poiché finora nessuno è stato in grado di costruire un modello di macchina di Turing e nessuna macchina esistente è riuscita finora a superare il test.
Perché nessuna macchina ha mai superato il test?
Un dispositivo in grado di superare il test è un programma in grado di operare opportuni collegamenti tra domande e risposte, non attraverso semplici processi associativi, bensì relazionandosi con l’interlocutore sulla base di un dialogo.
Un tale programma ha comportamenti intelligenti se è in grado di affrontare nuovi problemi utilizzando nozioni precedentemente apprese ed opportunamente modificate ed adattate alla risoluzione di problematiche nuove in contesti nuovi.
Il traguardo che ci si propone di raggiungere nella creazione di un’intelligenza artificiale è rappresentato da un modello di pensiero autodeterminante.
Nell’affrontare un problema, la macchina non giungerà alla soluzione seguendo uno schema prefissato di istruzioni elementari specificate nei minimi particolari, ma andrà per tentativi. Il risultato di ciascun tentativo verrà analizzato e confrontato coi successivi, usando i risultati ottenuti come base per i successivi “ragionamenti”.
Turing, in un suo celebre articolo, sostiene che “L’unico modo per essere sicuri che una macchina pensa è quello di essere la macchina stessa e di sentirsi pensare, l’unico modo di sapere che un uomo pensa è quello di essere quell’uomo”.
Per Turing pensare significa produrre pensieri e concatenarli, ed il segno più evidente del possesso di una tale capacità è l’espressione linguistica dei propri pensieri.
La scelta di limitarsi, durante il gioco dell’imitazione, all’interazione linguistica, permette di tracciare una netta linea di demarcazione tra le abilità fisiche e quelle intellettuali di un sistema intelligente, focalizzandosi sulle seconde. La somiglianza tra esseri umani e macchine è vista quindi nella produzione di espressioni che hanno un significato.
L’intelligenza è la capacità che entra in gioco nel momento in cui gli schemi comportamentali di cui si dispone si rivelano insufficienti per affrontare una determinata situazione. Essa si esprime attraverso uno sforzo di adattamento, di trasposizione, di ricerca di analogie e differenze, di classificazione, di generalizzazione e di discriminazione; queste sono tutte attività che una macchina, per quanto potente, non può svolgere da sola. La creatività è ciò che differenzia l’uomo dal computer, che rende l’intelligenza umana unica nel suo genere.
Nella concezione computazionale non c’è posto per la creatività, in quanto implica una violazione di ogni principio regolativo, che sta però alla base del funzionamento delle macchine.
Molti ricercatori sostengono che l’obiettivo primario dell’AI non sia la scoperta di una teoria generale del pensiero o la creazione fantascientifica di una mente sintetica, bensì l’invenzione di macchine utili, cioè di dispositivi intelligenti in grado di fungere da strumenti efficaci sia per lo studio della mente, sia per l’esecuzione delle varie attività sociali e lavorative.
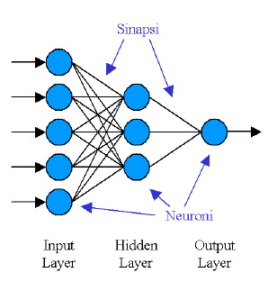
Le reti neurali artificiali sono dei sistemi di elaborazione dell’informazione che cercano di simulare all’interno di un sistema informatico il funzionamento dei sistemi nervosi biologici che sono costituiti da un gran numero di cellule nervose o neuroni collegati tra di loro in una complessa rete. Ogni neurone è collegato mediamente con una decina di migliaia di altri neuroni; le connessioni risultano quindi essere centinaia di miliardi. Il comportamento intelligente emerge dalle numerose interazioni tra le unità interconnesse.
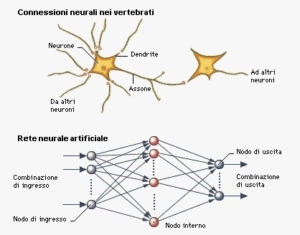
Alcune di queste unità ricevono informazioni dall’ambiente, altre emettono risposte nell’ambiente ed altre ancora comunicano solamente con le unità all’interno della rete: esse sono definite rispettivamente unità di ingresso (input layer), unità di uscita (output layer) ed unità nascoste (hidden layer).
Ciascuna unità svolge un’operazione molto semplice che consiste nell’attivarsi se la quantità totale di segnale che riceve supera una certa soglia di attivazione. Quando un’unità si attiva, emette un segnale che viene trasmesso lungo i canali di comunicazione fino alle altre unità cui è connessa; ciascun punto di connessione agisce come un altro che trasforma il messaggio ricevuto in un segnale eccitatorio od inibitorio, aumentandone o diminuendone nel contempo l’intensità a seconda delle caratteristiche individuali.
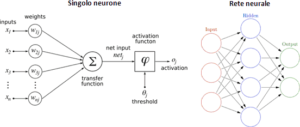
LA STRUTTURA
La struttura informatica utilizzata per riprodurre questo tipo di apprendimento è la rete neurale, una struttura software composta da unità chiamate neuroni, e da determinati collegamenti tra le stesse unità. I neuroni artificiali riproducono informaticamente la struttura dei neuroni presenti nel nostro cervello, come mostrato dalle foto seguenti, che rappresentano, rispettivamente un neurone biologico e un neurone informatico. Ogni neurone riceve segnali dai neuroni a esso connessi, segnali che viaggiano seguendo determinati collegamenti. Ai collegamenti sono assegnati pesi, cioè coefficienti secondo i quali i segnali passanti attraverso i collegamenti stessi sono amplificati o ridotti. Il funzionamento di ogni neurone è stabilito da funzioni logico-matematiche. Il neurone, quando riceve determinati segnali, verifica se quei segnali abbiano raggiunto il livello (la soglia) richiesta per la propria attivazione. Se il livello non è stato raggiunto,
il neurone rimane inerte; se invece il livello è stato raggiunto, il neurone si attiva, inviando a sua volta segnali ai neuroni con esso connessi.
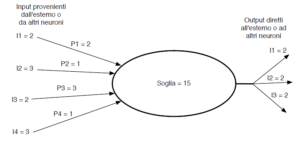
Per esempio, nell’immagine seguente al neurone sono inviati stimoli di valore 2, 3, 2 e 3. I pesi applicati a tali stimoli sono rispettivamente 2, 1, 3, e 1. Moltiplicando gli stimoli inviati al neurone per i relativi pesi, si ottengono gli input forniti al neurone: 2*2 = 4; 3*1 = 3; 2*3 = 6; 3*1 = 3. Il valore ottenuto sommando gli input (4 + 3 + 6 + 3), ovvero 16, è al disopra della soglia (ovvero 15) del neurone, che conseguentemente si attiverà, inviando messaggi di
valore 2 ai neuroni a esso collegati.
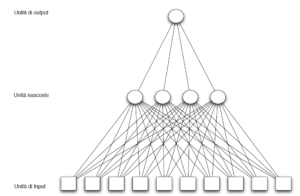
Combinando i neuroni otteniamo una rete neurale. Come risulta dalla figura seguente, alcuni neuroni della rete ricevono input dall’esterno (ad esempio da una base di dati, da una telecamera che riceve immagini dall’ambiente, da una tavoletta sulla quale si tracciano disegni o caratteri); alcuni neuroni, i cosiddetti neuroni nascosti, sono collegati solo con altri neuroni; alcuni neuroni, infine, inviano il loro output all’esterno della rete.
La tecnica più comune per addestrare una rete neurale consiste nel proporre alla rete una serie di esempi corretti, cioè un serie di coppie < input,output >, dove l’output indica il risultato corretto per l’input corrispondente.
Per esempio, se sogliamo addestrare una rete nel riconoscimento dei caratteri alfabetici ogni esempio consisterà di un segno grafico unito al carattere corrispondente. L’elaborazione degli esempi avviene nel modo seguente. Il sistema determina la propria risposta rispetto all’input indicato nell’esempio. Se la risposta differisce dall’output nell’esempio, la rete si riorganizza, cambiando la propria configurazione (i collegamenti o i pesi associati a essi) in modo da poter dare la risposta corretta (la stessa indicata nell’esempio) di fronte alla riproposizione dello stesso input. Dopo un conveniente addestramento, la rete acquista l’abilità di dare risposte corrette non solo nei casi contenuti nell’insieme degli esempi, ma anche in casi analoghi.
Il legame input-output, ovvero la funzione di trasferimento della rete, si ottiene da un processo di apprendimento non programmato, che si basa su dati empirici. Il processo può essere:
Supervisionato (supervised learning),
se si dispone di un insieme di dati per l’addestramento, comprendente esempi tipici di ingressi con le uscite loro corrispondenti.
L’obiettivo consiste nella previsione del valore di uscita per ogni valore valido di ingresso, basandosi soltanto su un numero limitato di esempi di corrispondenza (coppie di valori input-output).
La rete viene addestrata mediante un opportuno algoritmo (backpropagation); se ha successo, impara a riconoscere la relazione incognita che lega le variabili d’ingresso a quelle d’uscita, e può quindi fare previsioni anche nel caso in cui l’uscita non sia nota a priori.
Si fornisce alla rete un insieme di input ai quali corrispondono output noti (training set). Analizzandoli, la rete apprende il nesso che li unisce. In tal modo impara a generalizzare, ossia acalcolare nuove associazioni corrette input-output processando input esterni al training set.
Man mano che la macchina elabora output, si procede a correggerla per migliorarne le risposte variando i pesi. Ovviamente, aumentano i pesi che determinano gli output corretti e diminuiscono quelli che generano valori non validi.
Il meccanismo di apprendimento supervisionato impiega quindi l’Error Back-Propagation, ma è molto importante l’esperienza dell’operatore che istruisce la rete.
Il motivo risiede nel non facile compito di trovare un rapporto adeguato fra le dimensioni del training set, quelle della rete e l’abilità a generalizzare che si tenta di ottenere.
Un numero eccessivo di parametri in ingresso e una troppo potente capacità di elaborazione, paradossalmente, rendono difficile alla rete neurale imparare a generalizzare, perché gli input esterni al training set vengono valutati dalla rete come troppo dissimili ai sofisticati e dettagliati modelli che conosce.
D’altro canto, un training set con variabili scarse porta per la via opposta alla stessa conclusione: la rete, in questo caso, non ha sufficienti parametri per apprendere a generalizzare.
Il giusto compromesso, insomma, è un compito che necessita di molta preparazione ed esperienza.
Le reti feedforward come il MLP utilizzano l’apprendimento supervisionato.
Non supervisionato (unsupervised learning)
si basa su algoritmi d’addestramento riferiti ad un insieme di dati che include le sole variabili d’ingresso. Tali algoritmi raggruppano i dati d’ingresso ed individuano opportuni cluster per rappresentarli.
In una rete neurale ad apprendimento non supervisionato, la medesima riceve solo un insieme di variabili di input. Analizzandole, la rete deve creare dei cluster rappresentativi per categorizzarle. Anche in questo caso i valori dei pesi è dinamico, ma sono i nodi stessi a modificarli.
Esempi di reti ad apprendimento supervisionato sono SOM e la rete di Hopfield.
Per rinforzo (reinforcement learning)
in cui un opportuno algoritmo individua un certo modus operandi a partire da un processo di osservazione dell’ambiente esterno; ogni azione ha un impatto sull’ambiente, e l’ambiente produce una retroazione che guida l’algoritmo stesso nel processo di apprendimento.
Differisce dall’apprendimento supervisionato poiché non sono mai presentate delle coppie input-output di esempi noti e non si procede alla correzione esplicita di azioni subottimali.
Nelle reti neurali che apprendono mediante l’algoritmo di rinforzo, non esistono né associazioni input-output di esempi, né un aggiustamento esplicito degli output da ottimizzare.
I circuiti neurali imparano esclusivamente dall’interazione con l’ambiente. Su di esso, eseguono una serie di azioni.
Dato un risultato da ottenere, è considerato rinforzo l’azione che avvicina al risultato; viceversa, la rete apprende a eliminare le azioni negative, ossia foriere di errore.
Detto in altri termini, un algoritmo di apprendimento per rinforzo mira a indirizzare la rete neurale verso il risultato sperato con una politica di incentivi (azioni positive) e disincentivi (azioni negative).
Usando tale algoritmo, una macchina impara a trovare soluzioni che non è esagerato definire creative. Una rete neurale così implementata, per esempio, è stata utilizzata per giocare ad Arcade Breakout. Risultato: dopo sole 4 ore di continuo miglioramento, i circuiti hanno individuato una strategia di gioco mai ideata da un essere umano in questo videogame.
CLASSIFICAZIONE DELLE RETI NEURALI
Esistono molti tipi di reti neurali che si differenziano per alcune caratteristiche fondamentali:
Tipo di apprendimento. Può essere supervisionato o non supervisionato;
Tipo di utilizzo. Vi sono tre categorie basilari:
- Memorie associative: possono apprendere associazioni tra pattern in modo che la presentazione di un pattern A dia come output il pattern B, anche se il pattern A è impreciso o parziale (resiste al rumore).
- Simulatori di funzioni matematiche: comprendono la funzione che lega output ad input in base ad esempi forniti in fase di apprendimento. Da ciò consegue la capacità della rete di interpolazione ed estrapolazione sui dati del training set.
- Classificatori: permettono di classificare dati in specifiche categorie in base a caratteristiche di similitudine. In questa rete vige il concetto di apprendimento non supervisionato, in cui i dati di input vengono distribuiti su categorie non predefinite. L’algoritmo di apprendimento di una rete neurale e l’architettura dei collegamenti dipendono dal tipo di utilizzo della stessa.
Algoritmo di apprendimento.
Architettura dei collegamenti.
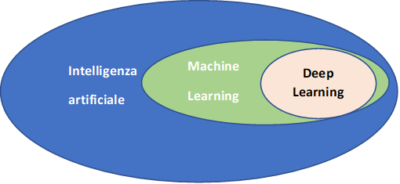
L’apprendimento automatico è un campo di intelligenza artificiale che utilizza tecniche statistiche per fornire ai sistemi informatici la capacità di “apprendere” (ad esempio, migliorare progressivamente le prestazioni su un compito specifico) dai dati, senza essere programmato esplicitamente.
L’apprendimento automatico inteso come abilità delle macchine (intese come computer) di apprendere senza essere state esplicitamente e preventivamente programmate.
La definizione più accreditata dalla comunità scientifica è quella fornita da un altro americano, Tom Michael Mitchell, direttore del dipartimento Machine Learning della Carnegie Mellon University:
«si dice che un programma apprende dall’esperienza E con riferimento a alcune classi di compiti T e con misurazione della performance P, se le sue performance nel compito T, come misurato da P, migliorano con l’esperienza E».
Detta in parole più semplici: il Machine Learning permette ai computer di imparare dall’esperienza; c’è apprendimento quando le prestazioni del programma migliorano dopo lo svolgimento di un compito o il completamento di un’azione anche errata.
Guardano il Machine Learning da una prospettiva informatica, anziché scrivere il codice di programmazione attraverso il quale, passo dopo passo, si indica alla macchina cosa fare, al computer vengono forniti solo dei set di dati inseriti in un generico algoritmo che sviluppa una propria logica per svolgere la funzione, l’attività, il compito richiesti.
Il nome machine learning fu coniato nel 1959 da Arthur Samuel. L’apprendimento automatico esplora lo studio e la costruzione di algoritmi in grado di apprendere e fare previsioni sui dati – tali algoritmi superano seguendo rigorosamente le istruzioni del programma statico facendo previsioni o decisioni basate sui dati: attraverso la costruzione di un modello dal campione ingressi. L’apprendimento automatico è impiegato in una serie di compiti di calcolo in cui la progettazione e la programmazione di algoritmi espliciti con buone prestazioni sono difficili o non fattibili.
L’apprendimento automatico è strettamente correlato (e spesso si sovrappone a) alle statistiche computazionali, che si concentra anche sul processo di previsione attraverso l’uso dei computer. Ha forti legami con l’ottimizzazione matematica, che fornisce metodi, teoria e domini applicativi sul campo. L’apprendimento automatico è talvolta associato al data mining, dove quest’ultimo sottocampo si concentra maggiormente sull’analisi dei dati esplorativi ed è noto come apprendimento non supervisionato (vedi sezione reti neurali artificiali).
Nel campo dell’analisi dei dati, l’apprendimento automatico è un metodo utilizzato per elaborare modelli e algoritmi complessi che si prestano alla previsione; in uso commerciale, questo è noto come analisi predittiva. Questi modelli analitici consentono a ricercatori, scienziati, ingegneri e analisti di “produrre decisioni e risultati affidabili e ripetibili” e di scoprire “intuizioni nascoste” attraverso l’apprendimento da relazioni storiche e tendenze nei dati.
DEEP LEARNING
Apprendimento profondo (noto anche come apprendimento strutturato o apprendimento gerarchico) fa parte di una più ampia famiglia di metodi di apprendimento automatico basati su rappresentazioni di dati di apprendimento, al contrario di algoritmi specifici per attività. L’apprendimento può essere supervisionato, semi-supervisionato o non supervisionato.
Architetture profonde come reti neurali profonde, reti di credenze profonde e reti neuronali ricorrenti sono state applicate a campi come la visione artificiale, il riconoscimento vocale, l’elaborazione del linguaggio naturale, il riconoscimento audio, il filtraggio dei social network, la traduzione automatica, la bioinformatica, la progettazione di farmaci e i programmi di gioco da tavolo, dove hanno prodotto risultati comparabili e in alcuni casi superiori agli esperti umani.
I modelli di apprendimento profondo sono vagamente ispirati dall’elaborazione delle informazioni e dai modelli di comunicazione nei sistemi nervosi biologici, ma presentano varie differenze dalle proprietà strutturali e funzionali dei cervelli biologici (specialmente il cervello umano), che li rendono incompatibili con le prove delle neuroscienze.
L’apprendimento approfondito è una classe di algoritmi di apprendimento automatico che:
- utilizzano una cascata di più livelli di unità di elaborazione non lineari per l’estrazione e la trasformazione di feature in cui, ogni livello successivo, utilizza l’output del livello precedente come input.
- apprendere in modo controllato (ad esempio, classificazione) e / o non supervisionato (ad esempio, analisi del modello).
- apprendere più livelli di rappresentazioni che corrispondono a diversi livelli di astrazione: i livelli formano una gerarchia di concetti.
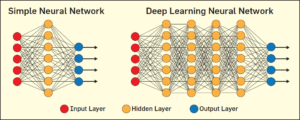
L’immagine seguente mette a confronto una rete neurale semplice e una profonda.
Nell’apprendimento approfondito, ogni livello impara a trasformare i suoi dati di input in una rappresentazione leggermente più astratta e composita. In un’applicazione di riconoscimento di immagini, l’input grezzo può essere una matrice di pixel; il primo livello di rappresentazione può astrarre i pixel e codificare i bordi; il secondo strato può comporre e codificare disposizioni di bordi; il terzo strato può codificare un naso e gli occhi; e il quarto livello potrebbe riconoscere che l’immagine contiene una faccia. È importante sottolineare che un processo di apprendimento approfondito può apprendere quali funzioni posizionare in modo ottimale in quale livello da solo.
Dal “deep” in “deep learning” si riferisce al numero di livelli attraverso i quali i dati vengono trasformati. Più precisamente, i sistemi di deep learning hanno una profondità sostanziale del percorso di assegnazione del credito (CAP). La PAC è la catena di trasformazioni da input a output. Le CAP descrivono le connessioni potenzialmente causali tra input e output. Per una rete neurale feedforward, la profondità dei CAP è quella della rete ed è il numero di livelli nascosti più uno (poiché lo strato di output è anche parametrizzato).
Per i compiti di apprendimento supervisionato, i metodi di deep learning annullano l’ingegneria delle caratteristiche, traducendo i dati in rappresentazioni intermedie compatte simili alle componenti principali e derivando strutture a strati che rimuovono la ridondanza nella rappresentazione.
Una rete neurale profonda (DNN) è una rete neurale artificiale (ANN) con più strati tra i livelli di input e di output. Il DNN trova la corretta manipolazione matematica per trasformare l’input in output, che si tratti di una relazione lineare o di una relazione non lineare. La rete si muove attraverso gli strati calcolando la probabilità di ogni uscita.
Ad esempio, un DNN che è addestrato a riconoscere le razze canine andrà oltre l’immagine data e calcolerà la probabilità che il cane nell’immagine sia una determinata razza. L’utente può esaminare i risultati e selezionare quali probabilità deve essere visualizzata dalla rete (oltre una certa soglia, ecc.) E restituire l’etichetta proposta. Ogni manipolazione matematica come tale è considerata un livello, e il DNN complesso ha molti livelli, da qui il nome di reti “profonde”.
L’obiettivo è che alla fine, la rete sarà addestrata a scomporre un’immagine in caratteristiche, identificare le tendenze esistenti in tutti i campioni e classificare nuove immagini in base alle loro somiglianze senza richiedere input umani.
I DNN possono modellare relazioni non lineari complesse. Le architetture DNN generano modelli compositivi in cui l’oggetto è espresso come una composizione stratificata di primitivi. I livelli extra consentono la composizione di feature da livelli inferiori, potenzialmente modellando dati complessi con un numero di unità inferiore rispetto a una rete poco profonda con prestazioni simili.
Le architetture profonde comprendono molte varianti di alcuni approcci di base. Ogni architettura ha trovato successo in domini specifici ma non è sempre possibile confrontare le prestazioni di più architetture, a meno che non siano state valutate sugli stessi set di dati.
I DNN sono in genere reti feedforward in cui i dati fluiscono dal livello di input allo strato di output senza ricorrere al loopback. Inizialmente, il DNN crea una mappa di neuroni virtuali e assegna valori numerici casuali, o “pesi”, alle connessioni tra di loro. I pesi e gli ingressi sono moltiplicati e restituiscono un’uscita tra 0 e 1. Se la rete non riconosce con precisione un particolare schema, un algoritmo regola i pesi. In questo modo l’algoritmo può rendere più influenti alcuni parametri, fino a quando non determina la corretta manipolazione matematica per elaborare completamente i dati (vedere esempio nella sezione reti neurali artificiali).
Rappresentazione a sottoinsiemi del sistema
Riconoscimento vocale automatico
Il riconoscimento vocale automatico su larga scala è il primo e più convincente caso di apprendimento profondo (deep learning). Gli RNN LSTM possono apprendere attività di “apprendimento molto profondo” che implicano intervalli di più secondi contenenti eventi vocali separati da migliaia di passaggi temporali discreti, in cui un passo temporale corrisponde a circa 10 ms.
Tutti i principali sistemi di riconoscimento vocale commerciale (ad esempio, Microsoft Cortana, Xbox, Skype Translator, Amazon Alexa, Google Now, Apple Siri, Baidu e iFlyTek, ricerca vocale e una gamma di prodotti vocali Nuance, ecc.) si basano sull’apprendimento approfondito e sfruttano l’Intelligenza Artificiale sia per il riconoscimento del linguaggio naturale sia per l’apprendimento e l’analisi delle abitudini e dei comportamenti degli utenti.
L’analisi in real-time di grandi moli di dati per la comprensione del “sentiment” e delle esigenze delle persone per migliorare customer care, user experience, servizi di assistenza e supporto ma anche per creare e perfezionare sofisticati meccanismi di ingaggio con attività che si spingono fino alla previsione dei comportamenti di acquisto da cui derivare strategie di comunicazione e/o proposta di servizi.
Declinando in un’altra area tematica si trovano le macchine automatiche di traduzione: attività in cui parole e frasi in una lingua vengono tradotte automaticamente in un’altra lingua. Sebbene le traduzioni automatiche ci siano già da un po’ di tempo, algoritmi di Deep Learning migliorano l’apprendimento delle relazioni tra più parole e la loro mappatura in una nuova lingua.
Gestione della Supply Chain
L’ottimizzazione e la gestione della catena di approvvigionamento e di distribuzione richiede ormai analisi sofisticate e, in questo caso, l’AI è il sistema efficace che permette di connettere e monitorare tutta la filiera e tutti gli attori coinvolti conferendo elevate caratteristiche di reattività e rispondenza alle esigenze del Mercato. I sistemi SCM, Supply Chain Management rappresentano casi molto significativi di applicazione dell’Intelligenza Artificiale relativo alla gestione degli ordini (in questo caso le tecnologie che sfruttano l’intelligenza artificiale non solo mirano alla semplificazione dei processi ma anche alla totale integrazione di essi, dagli acquisti fino all’inventario, dal magazzino alle vendite fino ad arrivare addirittura all’integrazione con il Marketing per la gestione preventiva delle forniture in funzione delle attività promozionali o della campagne di comunicazione).
Riconoscimento delle immagini
Un set di valutazione comune per l’immagine è il set di dati del database MNIST. MNIST è composto da cifre manoscritte e include 60.000 esempi di addestramento e 10.000 esempi di test. Come con TIMIT, le sue ridotte dimensioni consentono agli utenti di testare più configurazioni. È disponibile un elenco completo di risultati su questo set.
Il riconoscimento delle immagini basato sull’apprendimento profondo è diventato “superumano”, producendo risultati più accurati rispetto ai concorrenti umani. La prima volta è avvenuta nel 2011.
I veicoli addestrati all’apprendimento profondo ora interpretano le viste a 360°. Un altro esempio è la dismorfologia facciale. Novel Analysis (FDNA) utilizzato per analizzare un gran numero di sindromi genetiche.
La colorazione automatica di immagini in bianco e nero: gli algoritmi di Deep Learning possono capire il contesto delle immagini in bianco e nero e iniziare a inserire il colore dove necessario.
Sfruttando l’architettura della rete neurale, il software AI può attraversare un elevato numero di immagini su un database (es. Imagenet) per trovare il tono giusto per adattarsi a qualsiasi immagine. Questo approccio potrebbe essere utilizzato per colorare fotogrammi fissi di film in bianco e nero, filmati di sorveglianza o qualsiasi numero di immagini.
Pubblica Sicurezza
La capacità di analizzare grandissime quantità di dati in tempo reale e di “dedurre” attraverso correlazioni di eventi, abitudini, comportamenti, attitudini, sistemi e dati di geo-localizzazione e monitoraggio degli spostamenti di cose e persone offre un potenziale enorme per il miglioramento dell’efficienza e dell’efficacia della sicurezza pubblica, per esempio per la sicurezza e la prevenzione dei crimini in aeroporti, stazioni ferroviarie e città metropolitane oppure per la prevenzione e la gestione della crisi in casi di calamità naturali come terremoti e tsunami.
Elaborazione di arte visiva
Strettamente correlato ai progressi compiuti nel riconoscimento dell’immagine è la crescente applicazione delle tecniche di deep learning ai vari compiti di arte visiva. Ad esempio, a) identificando lo stile di un dipinto, b) “catturando” lo stile di un dipinto e applicandolo in modo visivamente piacevole a una fotografia arbitraria, e c) generando immagini impressionanti basate su campi di input visivi casuali.
La classificazione di oggetti: sono stati sviluppati algoritmi in grado di classificare gli oggetti di una fotografia come uno di un insieme di oggetti precedentemente noti.
Una variante più complessa di questa attività chiamata rilevamento oggetti comporta l’identificazione specifica di uno o più oggetti all’interno della fotografia e il disegno di un riquadro attorno ad essi.
Elaborazione del linguaggio naturale
Le reti neurali sono state utilizzate per l’implementazione di modelli linguistici dall’inizio degli anni 2000. LSTM ha contribuito a migliorare la traduzione automatica e la modellazione del linguaggio.
Ne deriva la possibilità di generare il linguaggio naturale, ossia riprodurre la voce umana da una macchina. Un esempio è Wavenet che è in grado di generare un discorso che imita qualsiasi voce umana e che suona più naturale dei migliori sistemi di sintesi vocale esistenti, riducendo il divario con le prestazioni umane di oltre il 50%.
Altre tecniche chiave in questo campo sono il campionamento negativo e l’incorporamento di parole. L’incorporamento di parole, come word2vec, può essere pensato come uno strato di rappresentazione di una parola correlata ad altre parole nel set di dati; la posizione è rappresentata come un punto in uno spazio vettoriale. Il livello di input consente alla rete di analizzare frasi e frasi utilizzando una grammatica vettoriale composizionale efficace. Gli auto-encoder ricorsivi costruiti in cima a un gruppo di parole possono valutare la somiglianza della frase e rilevare la parafrasi. Le architetture neurali profonde forniscono i migliori risultati per l’analisi della circoscrizione, analisi del sentimento, recupero di informazioni, comprensione della lingua parlata, traduzione automatica ed entità contestuale.
HealthCare: applicazione al mondo della Sanità
L’AI ha avuto il pregio di migliorare molti sistemi tecnologici già in uso da persone con disabilità (per esempio i sistemi vocali sono migliorati al punto da permettere una relazione/comunicazione del tutto naturale anche a chi non è in grado di parlare) ma è sul fronte della diagnosi e cura di tumori e malattie rare che si potranno vedere le nuove capacità dell’AI. Già oggi sono disponibili sul mercato sistemi cognitivi in grado di attingere, analizzare e apprendere da un bacino infinito di dati (pubblicazioni scientifiche, ricerca, cartelle cliniche, dati sui farmaci, ecc.) ad una velocità inimmaginabile per l’uomo, accelerando processi di diagnosi spesso molto critici per le malattie rare o suggerendo percorsi di cura ottimali in caso di tumori o malattie particolari. Non solo, gli assistenti virtuali basati su AI iniziano a vedersi con maggiore frequenza nelle sale operatorie, a supporto del personale di accoglienza o di chi offre servizi di primo soccorso.
La più ovvia applicazione dell’Intelligenza Artificiale al settore sanitario è nella gestione dei dati. Devono essere raccolti e immagazzinati tutta una serie di dati riguardanti la storia medica del paziente: raggi X, risultati di laboratorio, report sulle patologie del paziente, storia familiare e genoma. Ugualmente devono essere raccolti, conservati e gestiti i dati relativi alla salute del paziente: “diari” della salute; report elaborati dal paziente stesso attraverso un dispositivo; home diagnostics, dati provenienti da parenti, comunità di servizi e terze parti.
Una startup medica di San Francisco, Sense.ly, ha sviluppato un’infermiera virtuale. Si tratta di un avatar che aiuta medici e pazienti a monitorare e gestire la propria salute in modo migliore. L’avatar, che ha un volto sorridente e una voce piacevole, è un’interfaccia che utilizza il machine learning per supportare i malati cronici tra una visita dal dottore e l’altra. Un’analoga soluzione è quella fornita da AiCure, app sostenuta dal National Institutes of Health, che utilizza la webcam dello smartphone e l’AI per confermare in autonomia che i pazienti stiano rispettando le prescrizioni del medico. È risultata utile per i malati gravi, coloro che tendono a non rispettare le indicazioni del dottore e per i partecipanti ad esperimenti clinici.
Gestione delle truffe
La prevenzione delle frodi è una delle applicazioni più mature dove l’Intelligenza Artificiale si concretizza con quelli che tecnicamente vengono chiamati “advanced analytics”, analisi molto sofisticate che correlano dati, eventi, comportamenti ed abitudini per capire in anticipo eventuali attività fraudolente (come la clonazione di una carta di credito o l’esecuzione di una transazione non autorizzata); questi sistemi possono in realtà trovare applicazione anche all’interno di altri contesti aziendali, per esempio per la mitigazione dei rischi, la protezione delle informazioni e dei dati, la lotta al cybercrime.
RICONOSCIMENTO FACCIALE
Il sistema di riconoscimento facciale è composto da due parti. La prima, la rete neurale rilevatrice, accoglie il flusso di informazioni ripreso dalla videocamera e determina se vi sono persone. Una volta rilevate invia le informazioni riguardanti le persone alla rete neurale identificatrice che le confronta con una banca dati e rivela la presenza di corrispondenze.
Proprio come il cervello la rete neurale sfrutta i segnali. Ma descriverli nei termini a cui siamo abituati è impossibile. Viso tondo, sopracciglia sottili, capelli scuri, riga dei capelli a sinistra: sono concetti astratti che si formano dopo un’analisi gerarchica dei segnali visivi. Il processo vero e proprio di riconoscimento è molto più complicato perché si basa sull’analisi di una moltitudine di piccole caratteristiche. Così funziona anche l’intelligenza artificiale. Una fronte sporgente può essere descritta con 300 valori.
“È difficile dire quali simboli formino una rete neurale. È come una scatola nera: aprirla e vedere come funziona è un’operazione scientifica per niente facile. Sappiamo con certezza di avere un modello matematico che trasforma l’immagine delle persone in una lista di simboli. Facendo una cernita delle diverse opzioni cambiamo la struttura di questo modello per migliorarne il risultato finale”, racconta a Sputnik Aleksej Cessarsky, vice direttore generale dell’azienda che produce il sistema Videotech.
Il compito della rete neurale è quello di ridurre l’immagine a un insieme di simboli. La rete compie quest’azione con l’aiuto di formule matematiche che hanno la funzione di filtro. Si prende un riquadro di solito di 3×3 pixel e gli si sovrappone l’immagine del viso. Poi i 9 pixel del riquadro sono sostituiti da un solo pixel, solitamente quello più luminoso. Le dimensioni dell’immagine vengono ridotte di tre volte. Questa è un’operazione di convoluzione e la rete neurale implicata nel processo viene detta convoluzionale. Con le immagini sottoposte a convoluzione la macchina funziona più facilmente. In tal modo si riesce a distinguere un viso dall’altro.
“Come filtro si può usare solo il colore rosso, il colore dell’angolo in alto a sinistra del riquadro. Vi sono filtri che evidenziano chiaramente i bordi e le linee orizzontali. Vi sono formule che con un insieme di simboli effettuano trasformazioni matematiche”, spiega Cessarsky.
L’insieme di filtri, la loro consequenzialità, la struttura della rete neurale sono un know-how sul quale anche i programmatori dibattono. Affinché la rete neurale riconosca correttamente i volti, bisogna fornirle un’ampia banca dati di immagini. È un processo lungo che ha alla base molta interazione. A seconda della dimensione della banca dati e delle risorse di calcolo possono volerci settimane e mesi. Passo dopo passo il sistema impara a riconoscere i volti in modo sempre più preciso. I programmatori controllano solo che i vettori dei simboli (cioè il risultato del lavoro della rete neurale) portino il maggior numero di informazioni e permettano di fare un confronto. Per una rete neurale che è stata istruita l’età, il sesso e l’appartenenza religiosa di un volto non sono un problema.
“La rete neurale è in grado in pochi secondi di dire quale persona su dieci milioni si trovava nel campo visivo di 150000 telecamere. Un umano non potrà mai fare una cosa simile”, osserva Cessarsky.